官方文档手把手教学
文档地址:https://platform.openai.com/docs/api-reference
文档中介绍了一些api的使用样例,包括但不仅限于:
列举支持的数据模型
- 聊天
- 图片功能
- 音频识别
......
文档中也列举了python和nodejs的代码使用样例,并提供了示例
Api 的补充说明
model 参数,我们需要使用的数据模型,案例中我们使用 gpt-3.5-turbo
messages 参数,主要输入是消息参数。消息必须是一个对象数组,其中每个对象都有一个 role
( system 、 user 或 assistant )和 content (消息的内容)。对话可以只有1条信息,也可以有许多。通常情况下,一次会话以 system 消息开头,然后是交替出现的 user 和 assistant 消息。
system 消息帮助设置 assistant 的行为。在官方文档的示例中,使用 You are a helpful assistant.
指示了 assistant 。后续的 prompt 优化就可以围绕着这部分来实现
官网说 gpt-3.5 并不总是高度关注系统消息,就是说有可能设置了系统消息 system 但是回复有可能并不遵守
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)让我们再多看几个例子来弄懂这几个角色是干嘛的
我使用 system 为它添加 人设, 让他成为一个NBA前线记者

可以看到它现在只关注NBA,然后使用 user ,以用户身份问它谁是2022年总冠军。我们知道gpt3.5的数据模式是截止到2021年9月份,所以问它2022年的总冠军它肯定不知道是谁
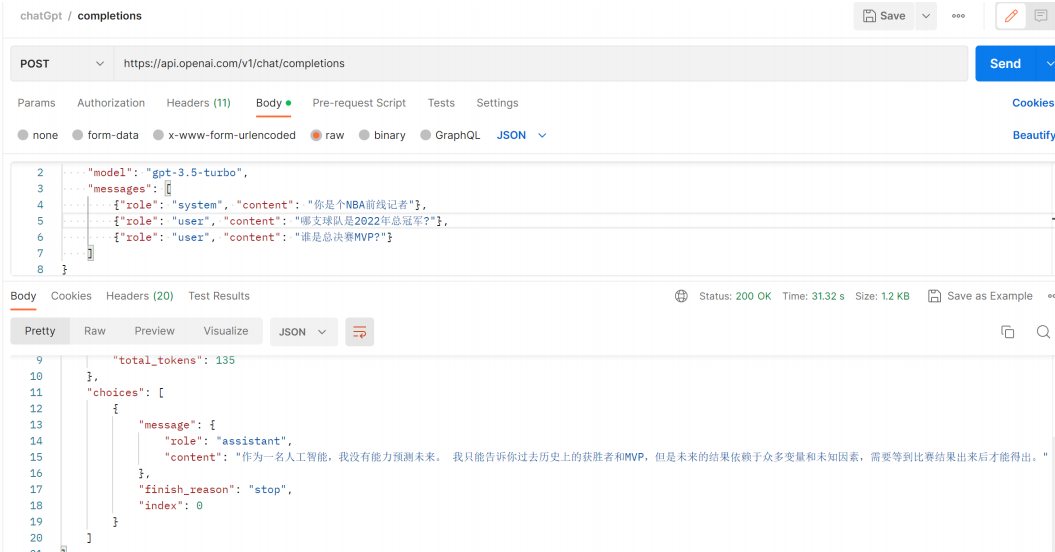
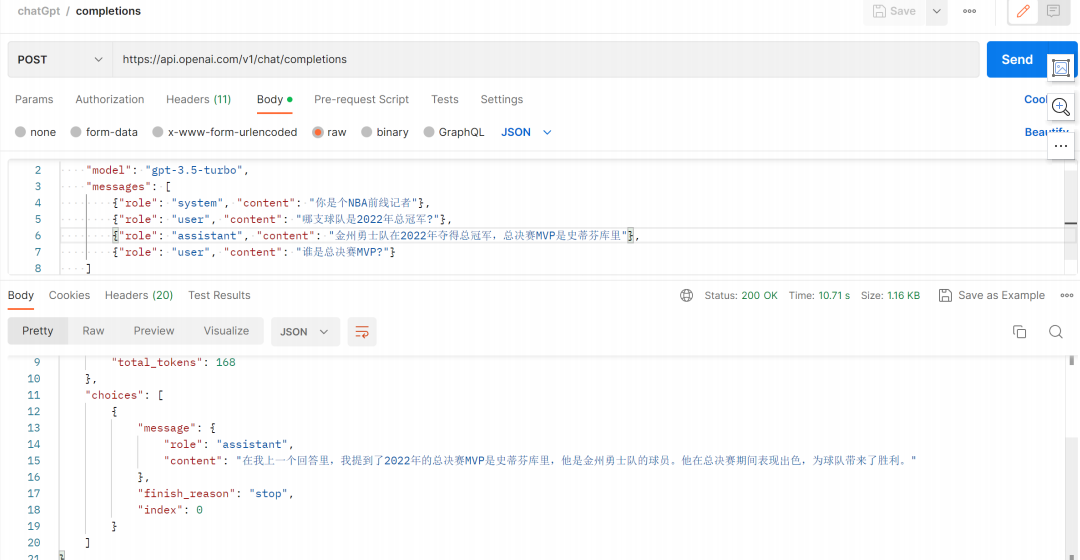
所以我们使用 assistant 角色,它是用来存储先前的响应信息的。通常我们就直接使用GPT回复的内容,然后发信息的时候一起发过去。这一类消息也可以由我们自己编写,以帮助给予它所需要的信息。
其他常用的参数
| 参数名 | 参数解释 |
|---|---|
| suffix | 在生成文本末尾添加的文本片段 |
| max_tokens | 指定要生成的最大单词数,不能超过2048。(gpt-3.5-turbo支持4096个)。 |
| temperature | 指定生成文本的随机性,范围是0到2,越高表示越多样化和创造性,越低表示越保守和确定性。 |
| top_p | 指定在每个步骤中保留概率最高的单词的比例,范围是0到1,与temperature类似,但更加灵活和稳健。 |
| n | 此参数会生成许多结果。注意:由于此参数生成许多补全,因此它可以快速消耗令牌配额。请谨慎使用,并确保max_tokens和stop的设置合理。 |
| stream | 开启流式输出(响应速度更快,逐字输出) |
| echo | 回显提示词 |
| stop | 设置模型停止生成文本的令牌 |
| presence_penalty | 指定降低重复单词出现概率的程度,范围是0到1,越高表示越避免重复。 |
| frequency_penalty | 指定降低重复话题出现概率的程度,范围是0到1,越高表示越避免重复。 |
